Base de datos relacional
Base de datos relacional
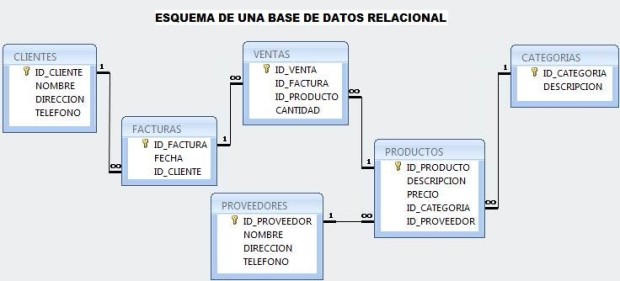
«Una base de datos relacional es un tipo de base de datos que cumple con el modelo relacional». Así, según esta definición de base de datos relacional, se trata de una base de datos que almacena y da acceso a puntos de datos relacionados entre sí. El modelo relacional es una forma intuitiva y directa de representar datos sin necesidad de jerarquizarlos.
Las bases de datos relacionales son el modelo más utilizado actualmente (postulado por primera vez en 1970 por Edgar Frank Codd).
Características y aspectos a tener en cuenta
Una base de datos relacional es, en esencia, un conjunto de tablas (o relaciones) formadas por filas (registros) y columnas (campos); así, cada registro (cada fila) tiene una ID única, denominada clave y las columnas de la tabla contienen los atributos de los datos. Cada registro tiene normalmente un valor para cada atributo, lo que simplifica la creación de relaciones entre los puntos de datos.
De tal manera que una de las principales características de la base de datos relacional es que evitar la duplicidad de registros y a su vez garantizar la integridad referencial, es decir, que si se elimina uno de los registros, la integridad de los registros restantes no será afectada. Además, gracias a las claves se puede acceder de forma sencilla a la información y recuperarla en cualquier momento.
Así mismo, no pueden existir dos tablas con el mismo nombre y la relación entre una tabla padre y una tabla hija se lleva a cabo a través de claves primarias (son la clave principal de un registro dentro de una tabla) y claves ajenas (se colocan en la tabla hija y contienen el mismo valor que la clave primaria del registro padre).
Para poder almacenar, administrar, consultar y recuperar los datos guardado en la base de datos relacional es necesario emplear un software específico, denominado sistema de gestión de bases de datos relacionales (RDBMS). Este software proporciona una interfaz entre los usuarios y/o las aplicaciones y la base de datos, además de contar con funciones administrativas para gestionar el acceso, almacenamiento y rendimiento.
Para escoger un RDBMS deberemos tener en cuenta las necesidades de la empresa y el tipo de datos y la cantidad que se van a manejar.
Ventajas y desventajas
Como la mayoría de los sistemas, la base de datos relacional tiene ventajas y desventajas que tener en cuenta a la hora implementarla, pero, cómo vamos a ver, en este caso las ventajas son lo suficientemente importantes como para que sea una de las bases de datos más empleada, incluso contando con algunas deficiencias.
Ventajas
Quizás la principal ventaja de la base de datos relacional reside en la sencillez del modelo relacional, que permite manejar grandes cantidades de datos con puntos de relación entre sí, gestionándolos de forma segura y conforme a unas normas y un modo uniforme.
Las bases de datos relacionales permiten mantener la uniformidad de los datos en todas las aplicaciones y copias de de la propia base, denominadas instancias (como por ejemplo, cuando hacemos una transferencia bancaria y esta se refleja en la aplicación del banco en nuestro móvil de manera inmediata). Las bases de datos relacionales garantizan que todas las copias de la base de datos tienen los mismos datos en todo momento.
Además, las bases de datos relacionales garantizan, como ya hemos mencionado, que no se produzca la duplicidad de registros. Y favorece la normalización al ser más comprensible y aplicable.
Así mismo, para evitar conflictos cuando varios usuarios o aplicaciones intentan acceder a los mismos datos en el mismo momento, pueden bloquear dicho acceso mientras los datos se están actualizando (como cuando estamos reservando unas entradas de cine numeradas).
Por su parte, la concurrencia se ocupa de gestionar las llamadas a consultas de varios usuarios o aplicaciones al mismo tiempo en la misma base de datos. A través de ella se proporciona el acceso corrector a los usuarios o aplicaciones según las normas o políticas definidas para el control de datos.
Desventajas
Como decíamos, las bases datos relacional también cuentan con algunas desventajas, principalmente, son deficientes a la hora de manejar datos gráficos, multimedia, CAD y sistemas de información geográfica, que necesitan un soporte más dinámico.
Tampoco permiten desarrollar tablas organizadas de formar jerárquica, es decir, no se puede crear un subfila, porque todas las filas están al mismo nivel jerárquico, por tanto no se puede emplear entidades subordinadas.
Puesto que las bases de datos relacionales acaban segmentándose en diferentes tablas separadas, esto provoca un rendimiento negativo a la hora de hacer consultas y obtener la información deseada.
Tipos
Como ya hemos mencionada más arriba, el software empleado para manejar una base de datos relacional es un sistema de Gestión de Bases de Datos Relacionales (RDBMS). Actualmente existen varios tipos de de gestores de BDR, entre ellos, los más usados son:
- Oracle
- MySQL
- Microsoft SQL Server
- PostgreSQL
- DB2
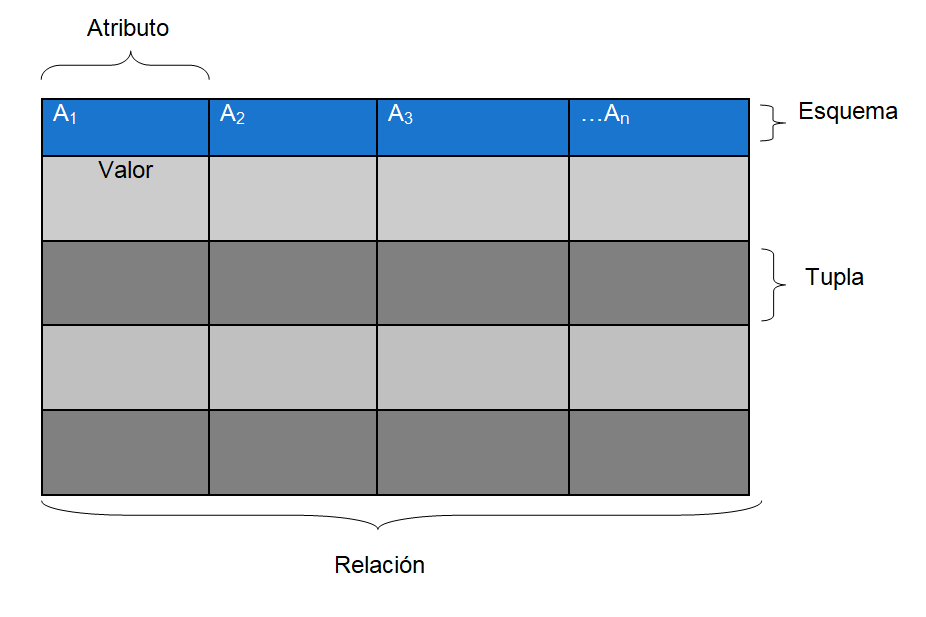
Estructura
La base de datos está dividida en dos secciones: el esquema y los datos. A través del esquema se define la estructura de la base de datos relacional, que almacena los siguientes datos:
- El nombre de cada tabla (o relación): es el conjunto de tuplas que comparten los mismos atributos, es decir, un conjunto de filas y columnas.
- El nombre de cada columna (atributo o campo): es un elemento etiquetado de una tupla (como por ejemplo, el número de la seguridad social de un empleado).
- El tipo de dato de cada columna.
- La tabla a la que pertenece cada columna.
- La fila (tupla o registro): es el conjunto de datos que representa un objeto simple.
Esta sería la estructura básica de una tabla de una base de datos relacional:
Así, una tabla con los datos de los empleados de una empresa podría verse así:
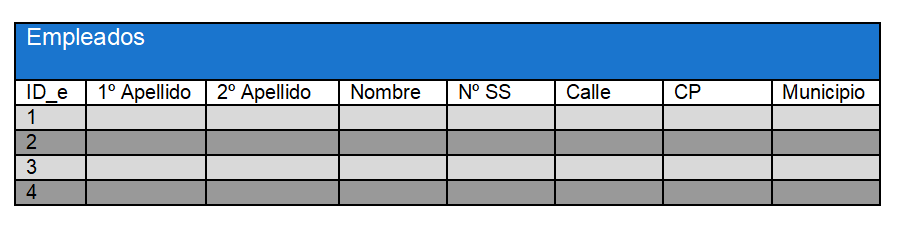
A cada empleado se le asigna un ID (o registro), que a su vez contiene información sobre cada empleado individual.
¿Cómo funcionan?
En las bases de datos relacionales, las tablas están relacionadas entre sí y han sido previamente establecidas (es decir, se debe diseñar previamente su estructura). Como ya hemos comentado, dentro de cada tabla hay un conjunto de datos o registros recogidos en columnas y filas. De manera que la relación entre una tabla principal y otra tabla subordinada se establece por medio las claves primaria o ajenas que se hayan establecido. Es a través de las claves por las que se hacen las relaciones
Por ejemplo, si en la tabla de empleados el ID es ID_e y nuestra empresa facilita una tablet a cada empleado, tendremos otra tabla que recogerá los datos de las tablets con una ID_t. Si incluimos la clave primaria de la tabla de las tablets (ID_t) como clave ajena en la tabla de los empleados, pondremos en relación ambas tablas, pudiendo ver qué tablet tiene cada empleado.
Gracias a las sentencias JOIN de SQL, es posible consultar varias tablas de datos de manera simultánea.
Además, existen claves índices que permiten acceder de manera más rápida a determinados datos, pudiendo tener diferentes combinaciones para consultar algunos datos o dato en concreto.
Finalmente, las relaciones que se pueden establecer entre los diferentes elementos de dos tablas en una base de datos relacional pueden se de tres tipos:
- Relaciones uno a uno cuando se establecen entre una entidad de una tabla y otra entidad de otra tabla.
- Relaciones uno a varios cuando se establecen entre varias entidades de una tabla y una entidad de otra tabla.
- Relaciones varios a varios cuando se establecen entre varias entidades de cada una de las tablas.
Comparativa base de datos relacional
Aunque la base de datos relacional es la más empleada actualmente, no esta de más hacer una pequeña comparativa con otras bases de datos que también se emplean en la actualidad, aunque a la hora de decantarse por una u otras dependerá de las necesidades de la empresa o la organización. O incluso será necesario combinar diferentes bases de datos para obtener mejores resultados o poder elabora análisis más completos.
vs no relacional
¿Una base de datos relacional vs no relacional? ¿Cuándo nos conviene usar uno u otro tipo de base de datos? Si conocemos de antemano la información que necesitamos registrar, podremos diseñar la estructura de la base de datos relacional y las tablas que necesitaremos para poder relacionarlas, de manera que sea sencillo y rápido acceder a los datos que queramos consultar en cada momento.
Una base de datos no relacional no tiene un identificador que sirva para relacionar un conjunto de datos con otros. Normalmente se emplea cunado la información se organiza mediante documentos o cuando no tenemos un esquema exacto de lo que vamos a almacenar.
vs NoSQL
¿Qué ocurre cuando tengo un gran volumen de datos que manejar? ¿Son apropiadas las bases de datos relacionales en estos casos? Enfrentamos aquí a la base de datos relacional vs NoSQL o No only SQL (no solo SQL). Estas bases de datos surgieron con la aparición de las redes sociales y el incremento de datos que supusieron. En principio no usan el lenguaje SQL o, si lo hacen, es solo de apoyo pero no para realizar las consultas.
Si en la base de datos relacional, los atributos de un elemento están en diferentes columnas, en las bases NoSQL se agrupan en una misma columna. Para realizar las consultas emplean lenguajes propios como JSON, CQL o GQL. Y no permiten JOINs dado el gran volumen de datos a manejar.
Así que si tu empresa o negocio registra y almacena grandes volúmenes de datos, lo más adecuado es decantarse por una base de datos NoSQL que permita su manejo. En otras palabras, las bases de datos relacionales se quedan cortas para el análisis del big data.
vs orientada a objetos
La base de datos orientada a objetos representa los datos en formas de objetos y clases; mientras el objeto puede ser el resultado de una búsqueda, la clase es una colección de objetos.
Así, los objetos similares se agrupan en una clase y cada objeto de una clase particular se llama instancia. Gracias a las clases, el programador puede definir datos que no están incluidos en el programa. Además, para intercambiar datos entre sí, las clases usan mensajes llamados métodos y cuentan con una propiedad llamada herencia, que permite que una subclase herede las propiedades que se han definido para una clase.
Este modelo permite crear una superclase combinando todas las clases que reduce la redundancia de datos y la reutilización de clases, que a su vez facilita un mantenimiento más fácil de los datos. Además, permite almacenar diferentes tipos de datos (audio, vídeo, imagen…).
Por lo tanto, entre base de datos relacional vs orientada a objetos, debemos considerar las necesidades de nuestra empresa o negocio. Las bases de datos orientadas objetos parecen muchos más útiles y, de hecho lo son para campos como el CAD, las aplicaciones científicas y otros tipos de aplicaciones específicas. Sin embargo, puede que para una empresa que solo quiera tener una base de datos de sus empleados, una base de datos relacional puede ser suficiente.
vs transaccional
En cuando a la base de datos relacional vs transaccional, lo cierto es que la primera necesita de la segunda para asegurar la integridad y corrección de los datos en caso de que sea necesario registrar transacciones (como por ejemplo las transferencias online de un banco o las ventas de un ecommerce).
Las bases de datos transaccionales garantizan que si se produce un fallo en el sistema cuando se está llevando a cabo una transacción, esta no se finalizará ni se registrará, volviendo al estado original. Es decir, o se dan todos los pasos de forma correcta o no se completa la transacción.
Ejemplos
Finalmente vamos a ver unos ejemplos de base de datos relacional para ilustrar lo que hemos ido viendo a lo largo de la entrada.
Si nuestra empresa realiza envíos de materiales a clientes, primero tendremos una tabla con la información de estos clientes, en la que cada fila o tupla corresponderá a los datos de cada cliente en concreto, nombre, dirección, datos de facturación… La base de datos asignará una clave única a cada fila, una ID_c (por ejemplo),
La segunda tabla contendrá información de los pedidos que realizan los clientes. Cada registro incluirá el ID_c del cliente que los hizo el pedido, el producto, la cantidad, etc., pero no especificará el nombre ni los datos del cliente.
El dato en común de estas tablas es la clave, ese ID_c; a través de esta columna en común, la base de datos establecerá una relación entre las dos tablas. Así, cada vez que se haga un pedido, la aplicación que los procesa recurrirá a la tabla de pedidos del cliente y a través del ID_c, extraerá la información correcta sobre el pedido, los datos de facturación y la dirección de envío.
Si seguimos con el ejemplo anterior que hicimos con las tablets; el dato en común entre la tabla de empleados y la de las tablets será el ID_e, es decir, la clave que dimos a cada empleado, de manera que si queremos saber qué tablet está utilizando cada empleado, podemos recurrir a una de los tablas, que a través de ese dato en común, pondrá en relación ambas tablas y extraeremos como resultado la consulta hecha.



Comentarios
Publicar un comentario